|
|
一、现有问题
由于Redis本身的一些特性(例如复制)以及使用场景,造成Redis不太适合部署在不同的机房,所以通常来看Redis集群都是在同一个机房部署的。虽然Redis集群自身已经具备了高可用的特性,即使几个Redis节点异常或者挂掉,Redis Cluster也会实现故障自动转移,对应用方来说也可以在很短时间内恢复故障。但是如果发生了机房故障(断电、断网等极端情况),如果应用方降级或者容错机制做的不好甚至业务本身不能降级,或者会丢失重要数据,或者可能瞬间会跑满应用的线程池造成服务不可用,对于一些重要的服务来说是非常致命的。
为了应对像机房故障这类情况,保证应用方在这种极端情况下,仍然可以正常服务(系统正常运行、数据正常),所以需要给出一个Redis跨机房的方案。
二、实现思路和目标:
1.思路
- 使用CacheCloud开通两个位于两个不同机房的Redis-Cluster集群(例如:兆维、北显):一个叫major,作为主Redis服务,一个叫minor,作为备用Redis服务。
- 开发定制版的客户端,利用netflix的hystrix组件能够解除依赖隔离的特性,在major出现故障时,将故障隔离,并将请求自动转发到minor,并且对于应用的主线程池没有影响。(有关hystrix的请求流程流程见下图,有关hystrix使用请参考:http://hot66hot.iteye.com/blog/2155036
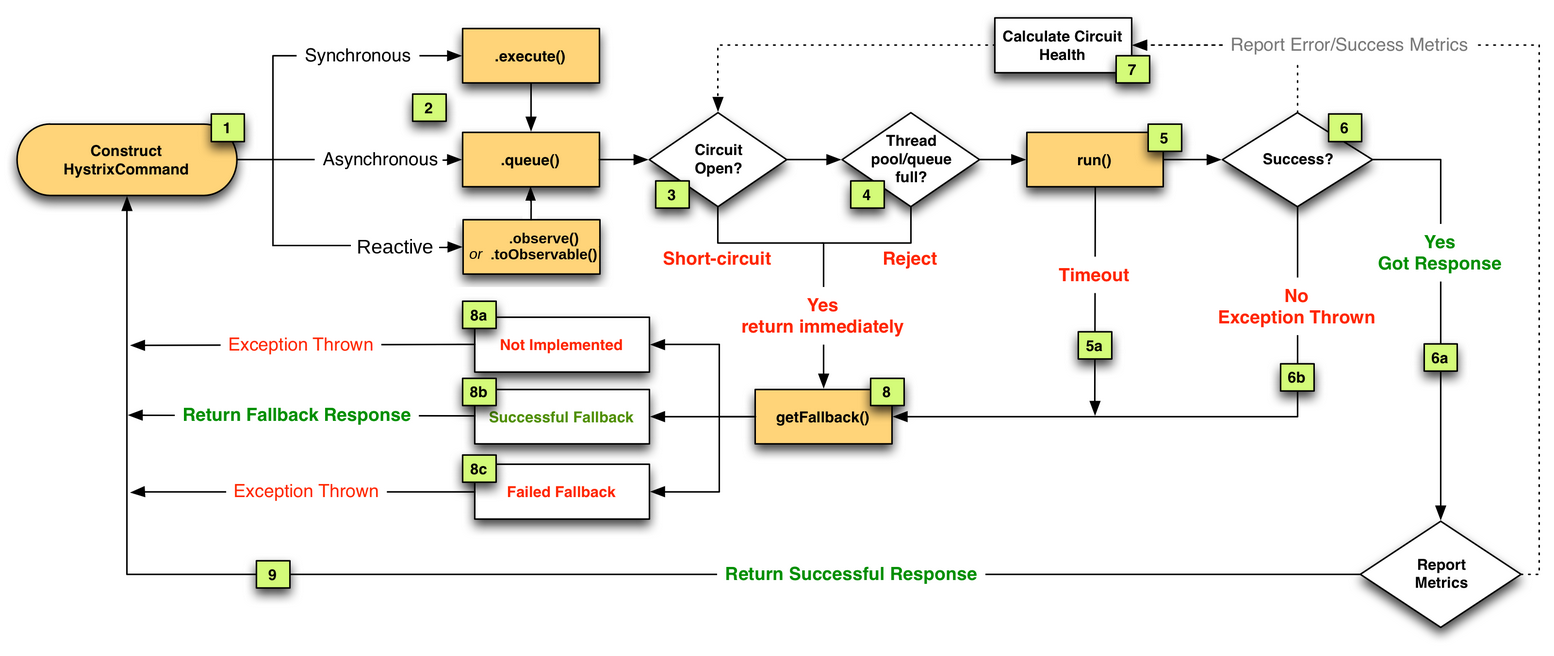
2.实现目标:
- 客户端易接入,如同使用Jedis API一样。
- 真正实现跨机房的故障转移。
- 依赖隔离,也就是说即使Redis出现问题,也不会影响主线程池。
- 读取数据正常。
- 写数据尽可能一致。
- 更多的故障转移可配置参数(hystrix):例如隔离线程池大小,超时等
- 暴露相关统计数据和报表:如jmx和hystrix-dashboard
三、实施:
- 1.利用hystrix能够隔离依赖的特性,为major和minor分别放到不同的线程池中(与应用的主线程池隔离)
- 2.客户端接口和初始化方法:由于是定制化客户端,所以暂时没有通用的方法,所有的API需要自己实现。
|
|
初始化方法,需要传入两个初始化好的PipeLineCluster
|
|
|
|
- 3.读操作方案:如下图,正常run指向到major, 异常(2.1图中所有指向getFallback)指向到minor。
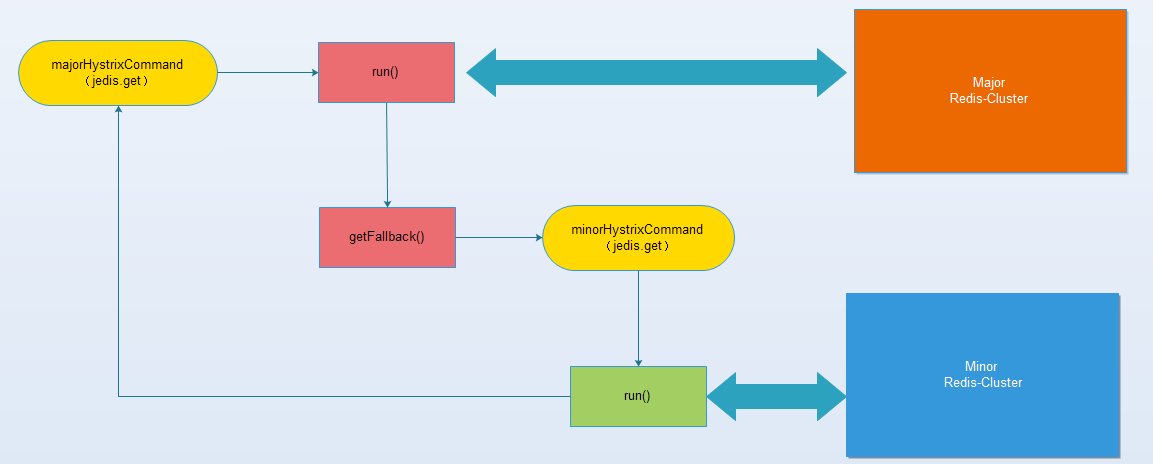
例如:正常情况下都是从majorPipelineCluster读取数据,当出现非正常情况时(hystrix阀门开启、线程池拒绝、超时、异常)等情况时,走minorPipelineCluster的逻辑
基础类
读命令类
例如get(String key)命令
|
|
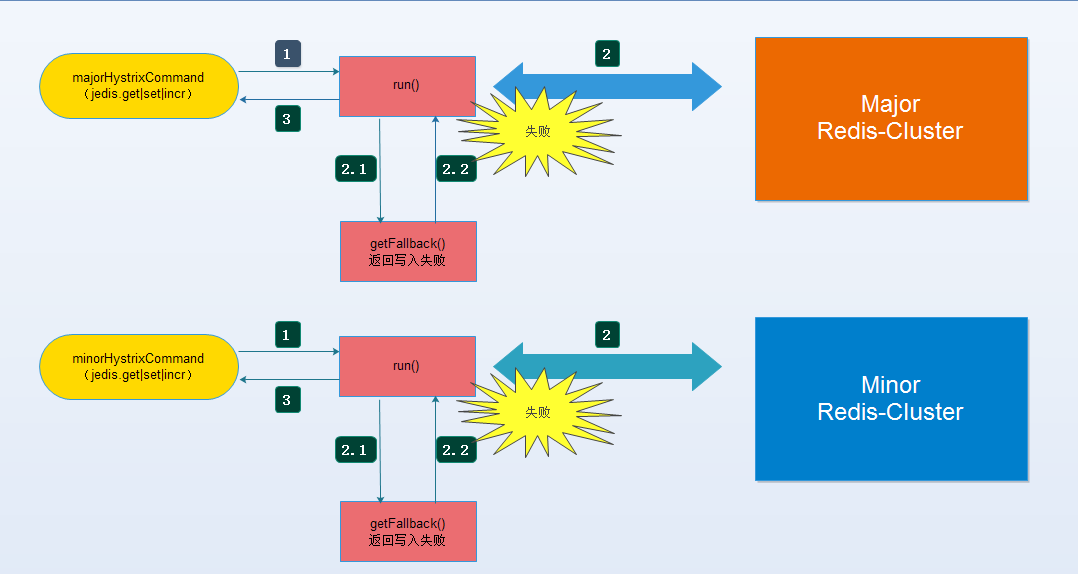
- 4.写操作方案目标:尽可能双写,如果发生故障暂时只是做了隔离,没有做数据同步处理(未来会考虑接入MQ),目前只把写入的结果返回给应用方,应用方来维持一致性。
MultiWriteResult类,四个成员变量分别为:
| 序号 | 参数 | 含义 |
|---|---|---|
| 1 | DataStatusEnum majorStatus | 主集群执行结果状态 |
| 2 | T majorResult | 主集群执行Redis命令结果 |
| 3 | DataStatusEnum minorStatus | 备用集群执行结果状态 |
| 4 | T minorResult | 备用集群执行Redis命令结果 |
|
|
例如set命令
四、对外暴露的数据和报表:
(1) hystrix-dashboard报表:实时统计图。
(2) jmx相关数据:major和minor相关统计,run和fallback调用次数、异常次数。
五、测试读:
1.major服务正常,但是major的线程池确实不够用
(1) 测试代码
测试方法:major的线程池设置小一些,请求的并发量大一些,每个线程做1000次随机读并返回主线程
测试验证:每个请求都有返回结果(前提是key是存在的)
|
|
(2) 故障转移:
major线程池偶尔吃满,将线程拒绝,并执行降级逻辑,将请求自动转移到minor。
|
|
(3) hystrix-dashbord: 部分被major线程池拒绝的线程(紫色),通过fallback转移到minor线程池中执行。

(4) 最终结果,返回非空的结果的个数等于请求个数
|
|
2. major服务异常,造成major的线程池不够用,或者存在大量异常,大量超时等等
(1) 测试代码:
测试方法:直接利用Redis的debug sleep seconds命令使得Redis暂时不提供服务。
测试验证:每个请求都有返回结果(前提是key是存在的)
|
|
(2) 故障转移:
直接major线程池的阀门打开了,所有请求执行降级逻辑,将请求自动转移到minor。
|
|
(3) hystrix-dashboard
major的熔断器阀门已经打开,请求都转移到迁移到minor,之后major恢复,流量又回到major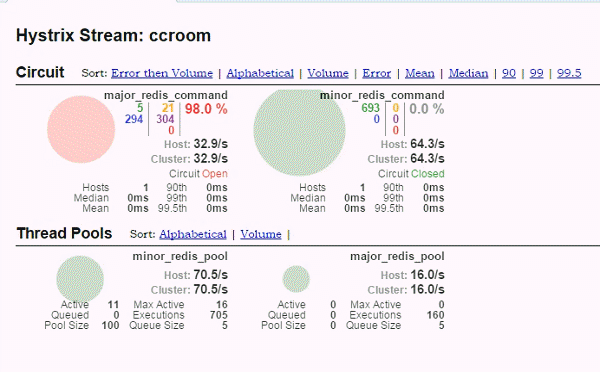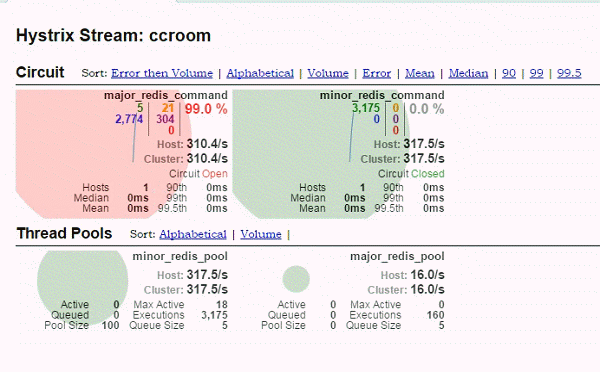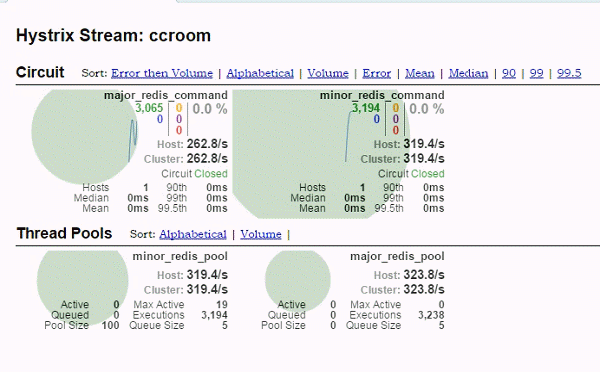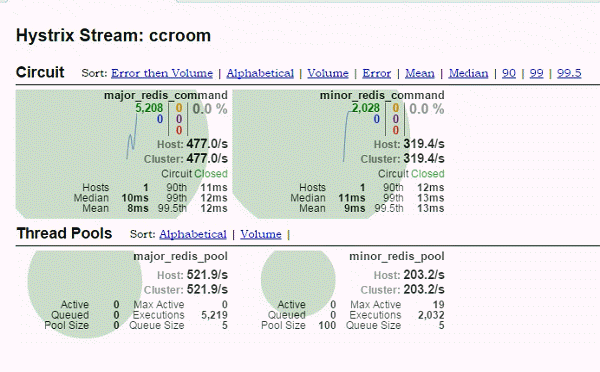
(4) 最终结果:
返回非空的结果的个数等于请求个数
|
|
六、测试写:
1.major异常:
(1)测试代码
直接sleep major,20个线程,一共写1000次,每个线程50个key 。
|
|
(2) 异常:major出现大量超时,major写入失败
|
|
(3) dashboard:
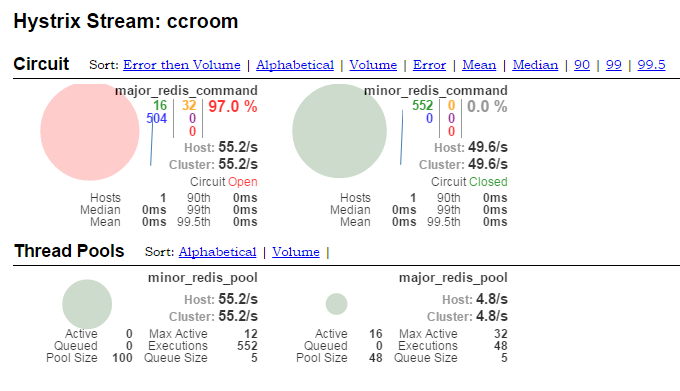
(4) 最终结果:
一共写了1000次,成功写入22次,部分成功写入了978次。
|
|
七、问题和展望
- 由于是定制化客户端,目前只支持部分Redis命令API,后续需要添加
- 在出现故障时,读正常,但是双写会出现major和minor数据不一致的情况。(可以考虑利用MQ机制来解决这个问题),目前使用打印日志的形式记录。
- …………..